
EdTech Platform Maintenance Case Study: How Kaopiz Kept 4 Live Systems at 99.6% Uptime
In every software maintenance outsourcing conversation I have with EdTech operators, maintenance comes up, but rarely as the first agenda item. It’s usually buried under questions about development costs or team size. That changes fast the first time a teacher can’t access lesson materials mid-class, or a guardian’s grade notification goes missing for three days.
This case study documents a real 12-month EdTech platform maintenance engagement, the team model, the triage structure, and the outcomes we measured. We’re keeping the client’s name confidential at their request; every detail and number in this article is accurate.
If you’re evaluating maintenance partners for a live education platform, this is what choosing the right structure actually delivers.
Key Takeaways
- Client: Japan-based EdTech company, private tutoring school network serving students, teachers, and guardians across 4 platforms
- Scope: 12-month ongoing maintenance of FDB-EX, GOKU, FORESTA, and JUKUKOUSI
- Tech stack: PHP, VueJS, Angular, Flutter
- Model: Dedicated on-site engineers with P1/P2/P3 severity-based triage, proactive + reactive split
- Results: 99.6% uptime, 57% faster incident response, 35% faster improvement delivery, 28% less management overhead, 25% higher end-user satisfaction
The Client: A Japan EdTech Company Serving 3 User Groups Across 4 Platforms
Our client is a Japan-based education company operating a network of private tutoring schools across the country. Their platform serves 3 distinct user groups simultaneously, students, teachers, and guardians, across 4 web and mobile systems, each handling a different function and built on a different part of the stack.
As their school network expanded, so did the complexity of keeping these systems running reliably. They needed more than a vendor on a ticketing queue. They needed an engineering team embedded closely enough to understand every system’s behavior, respond quickly when things broke, and proactively identify problems before users felt them.
That’s where Kaopiz came in.
The Challenges: Why Multi-System EdTech Maintenance Fails
I’ve seen EdTech operators successfully manage one platform with a small internal team. I’ve rarely seen the same approach scale to three or four. The failure mode isn’t technical; it’s structural. Each additional system multiplies the number of failure patterns your team needs to hold in their heads simultaneously.
Problem 1: Each System Had Its Own Failure Pattern
Across 4 systems built at different periods on different codebases (PHP, VueJS, Angular, Flutter), engineering intuition doesn’t transfer. A fix that works in GOKU’s analytics layer has no predictable relationship to how FDB-EX handles messaging failures. The client’s internal team was managing 4 separate failure modes with no standardized process to triage or prioritize them.
Problem 2: Maintenance Backlogs Were Disrupting School Operations
An unresolved bug in the communication system didn’t affect one user, it disrupted an entire school’s information flow for the day. Without severity classification, a minor UI complaint sat in the same queue as a P1 classroom-blocking failure. Resolution timelines were inconsistent, and the downstream impact on teachers and guardians was compounding.
Problem 3: Speed and System Context Had to Coexist
Fast response without context creates more problems than it solves. Any engineer touching these systems needed to understand not just the fix, but how that fix rippled across 4 interconnected platforms in active use. That combination, speed and depth, was what the existing setup couldn’t deliver at scale.
The real cost of poor maintenance isn’t the bug itself. It’s the pattern of deferred fixes that accumulates until a small issue becomes a classroom disruption. That’s what we were hired to stop.
Our Solutions: What Kaopiz Maintained and How We Approached Each System
Rather than a ticketing-based support contract, Kaopiz took on dedicated maintenance ownership across all 4 systems.
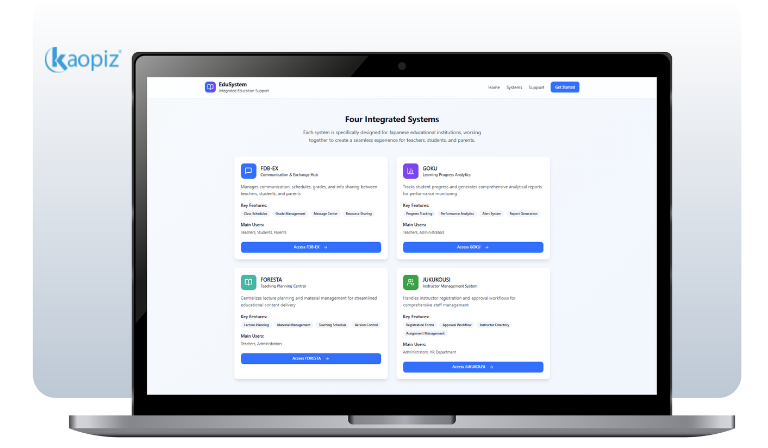
FDB-EX: Student–Parent–Teacher Communication Layer
FDB-EX is the most user-facing of the four; it handles scheduling, grade sharing, school announcements, and direct messaging. Any degradation here is immediately felt by end users. A delayed notification or failed message delivery doesn’t just frustrate a parent; it creates a trust gap between the school and the families it serves.
We stabilized the messaging pipeline, reduced notification delivery failures, and standardized the data-sharing format across school locations. We also built a response playbook from documented failure patterns, cutting diagnosis time for recurring issues significantly.
GOKU: Student Progress Tracking and Analytics
GOKU gives instructors a real-time view of each student’s academic progress. Data accuracy under load was the core challenge, the analytics engine needed to reflect updates without lag, particularly during term-end reporting when every instructor across every location is generating summaries simultaneously.
We improved report generation performance, resolved edge cases in cross-branch data sync, and stabilized bulk exports that had been unreliable under load. The goal was simple: no instructor should face a data gap during the window that matters most.
FORESTA: Lecture Management for Instructors
FORESTA handles lecture planning, material uploads, lesson scheduling, and content distribution. The system had accumulated UX debt that was quietly reducing instructor efficiency, too many steps to publish weekly materials, a fragile file management architecture as content volume grew.
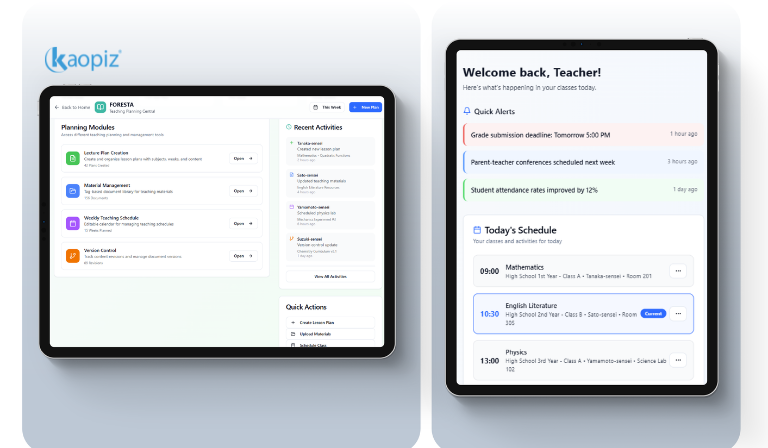
We restructured the file management layer, reduced task completion steps, and introduced upload validation that caught errors before they reached instructors. Fewer error states mean fewer support escalations.
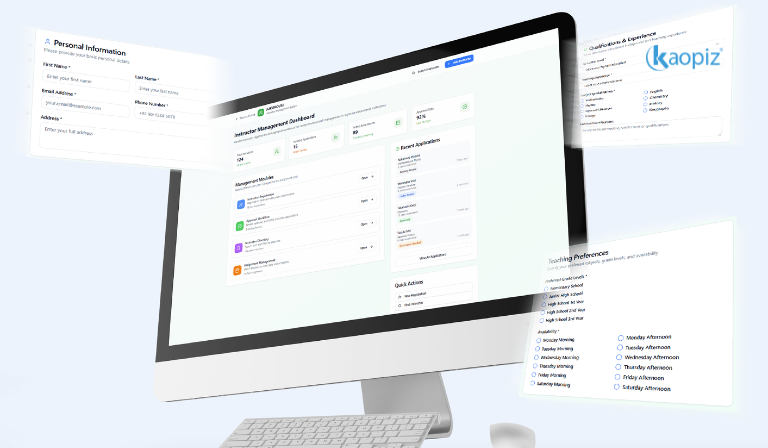
JUKUKOUSI: Instructor Registration and Approval Workflow
JUKUKOUSI manages instructor onboarding, from application through approval to activation. The workflow had accumulated edge cases: stalled applications without notification, status updates that failed to trigger next steps, inconsistent approval flows between administrators.
We restructured the workflow logic, added transparent status tracking for all parties, and eliminated the category of stalled applications entirely. A clean onboarding flow is a trust signal for every instructor who joins the platform.
How Kaopiz Structured the Maintenance Team and Triage Process
In my experience, most EdTech platform maintenance engagements fail not because of technical gaps, but because no one defined who owns what when something breaks at 7am. This is how we solved that for a client running 4 live platforms.
Why On-Site Placement Matters for Live Education Platforms
This is a decision I’d push back on any vendor who defaults to remote-only for a live multi-system engagement. An engineer who attends the client’s daily standup understands which system is under pressure this week, which upcoming school events will drive usage spikes, and which fixes need real-context testing — not just isolated staging validation.
We assigned dedicated engineers at the client’s site. The difference in response quality between an embedded engineer and one working off a shared remote queue is significant. Remote-first maintenance works for stable, low-complexity systems. This wasn’t that.
Proactive vs. Reactive: How We Split Maintenance Capacity
The most common failure mode in education platform maintenance engagements is letting the reactive queue consume all available capacity. You fix what’s reported. You never get ahead of what’s coming. Over time, that means more incidents, not fewer.
We split capacity deliberately across both modes from day one.
- Reactive work: failure triage, hotfixes, user-reported bugs. A P1/P2/P3 severity classification system routed issues to the right engineer immediately, P1 failures triggered same-session response, P2/P3 were queued with defined SLAs.
- Proactive work: monitoring, performance review, and identifying failure points before they reached production. One example: we identified a load bottleneck in GOKU’s report generation pipeline before the term-end reporting period and resolved it before a single instructor experienced slowdown.
Results After 12 Months of Ongoing Engagement
Numbers tell part of the story. Here’s what 12 months of structured maintenance ownership actually delivered across all 4 platforms.
| Metric | Outcome | What Changed |
|---|---|---|
| System uptime | 99.6% across 4 platforms | Severity triage eliminated the unstructured queue; P1 failures resolved before the next school session |
| Incident response time | 57% faster | SLA by severity replaced ad-hoc response; P1 = same-session resolution |
| Improvement delivery speed | 35% faster | Embedded engineers cut time from request to deployment significantly |
| Critical requests within SLA | 100% of P1 and P2 | First time client consistently met SLA targets for critical improvement requests |
| Management overhead | 28% reduction | Single unified process across 4 systems replaced 4 separate workflows |
| End-user satisfaction | +25% year-over-year | Fewer classroom disruptions; fewer escalations from school administrators |
57% Faster Incident Response, 99.6% Uptime Across All 4 Platforms
Before Kaopiz took over, failure response followed no standardized path — issues were reported, queued, and addressed whenever capacity allowed. Critical bugs affecting classrooms in active session waited in the same queue as minor UI complaints.
After establishing a severity-based triage system, every P1 failure — anything directly disrupting teachers, students, or guardians — was routed to the responsible engineer immediately and resolved before the next school session opened. This structured approach reduced failure response time by 57% and drove system uptime to 99.6% across all 4 platforms.
The client’s internal team stopped receiving escalations from school administrators about unresolved system issues, a pattern that had been consistent before the engagement began.
Beyond reactive response, the proactive monitoring stream caught several high-impact failures before they reached production. The most significant: a load bottleneck in GOKU’s report generation pipeline identified and resolved ahead of the term-end reporting period — a peak usage window when a slowdown would have affected every instructor across every location simultaneously.
35% Faster Delivery, 100% of Critical Requests Within SLA
Education platforms don’t stay still. Curriculum changes, new regulatory requirements, and evolving classroom workflows generate a continuous stream of improvement requests from the field. Previously, these requests took weeks to assess, prioritize, and ship.
With dedicated engineers already embedded in the system architecture, the lead time between a request being raised and a solution being deployed dropped by 35%. More critically, 100% of P1 and P2 improvement requests were resolved within SLA, a benchmark the previous setup had never consistently met. Instructors and administrators began seeing their feedback reflected in the systems within days rather than weeks.
28% Less Management Overhead
Before the engagement, the client’s internal team was spending significant time just coordinating maintenance across 4 systems with no unified process, separate queues, different response timelines, manual status follow-ups. Standardizing the process across all 4 platforms reduced that overhead by 28%. The team shifted from managing maintenance operations to reviewing improvement proposals. That’s a meaningful change in how internal capacity gets spent.
25% Higher End-User Satisfaction
System reliability is invisible when it works. It becomes very visible when it doesn’t: a missed announcement, a grade that didn’t sync, a lecture file that failed to upload before class. Over 12 months, the frequency of these end-user-facing failures decreased consistently across all 4 systems. End-user satisfaction scores improved 25% year-over-year, with school administrators raising fewer platform-related complaints than at any point in the previous year.
“Thank you very much for your help. We have many issues where the specifications have not yet been finalized, so we are always grateful for your many suggestions. We look forward to working with you in the future.”
— Operations Team, Japan EdTech Client
What Makes EdTech Platform Maintenance Different from Standard IT Support
I make this distinction clearly in every vendor evaluation conversation, because it changes what you need from a partner. Standard IT support is built around a stable, known product. You learn the system, document the failures, optimize response time. Education platforms break that model in three specific ways.
- Non-technical users with zero tolerance for downtime. A teacher mid-lesson doesn’t troubleshoot; they abandon the tool and improvise. Every minute of unavailability has a direct cost in classroom quality, not just user frustration.
- The release cycle never stops. Education companies update platforms continuously, curriculum changes, new regulations, competitive feature pressure. What you maintained last month may behave differently next month. Your maintenance partner needs to adapt in real time, not just maintain a static baseline.
- Multiple user groups create conflicting priorities. A fix that improves the student experience might temporarily affect the instructor workflow. Multi-system EdTech maintenance requires systems thinking, not just patching individual components in isolation.
Is This Engagement Model Right for Your EdTech Platform?
When I assess whether a dedicated on-site maintenance model makes sense for a client, I look for four conditions. If most of them are true, the overhead of a shared remote queue will cost you more than a dedicated structure within 6 to 12 months.
- Your systems are live and actively used, not in development
- Your user base is non-technical and intolerant of downtime
- Your platform is evolving continuously, not static
- You need both fast response and deep system context from the same team
If you operate more than 2 user-facing systems and your team is currently handling maintenance reactively — responding to reports rather than monitoring proactively — the overhead compounds over time. Every deferred fix becomes a future incident. Every incident affects real users in real classrooms.
Kaopiz can assess your current maintenance setup and identify where the highest-risk gaps are, without a long procurement process.
Conclusion
EdTech platform maintenance at scale isn’t a support ticket problem; it’s an engineering ownership problem. The difference between a reactive vendor and a dedicated team shows up in uptime numbers, in how fast improvements reach instructors, and ultimately in whether teachers and students trust the tools they depend on every day.
The outcomes above are what 12 months of structured maintenance ownership looks like across 4 live systems. If you need multi-platform EdTech support, we’re happy to walk through what that engagement would look like for your situation.
FAQs
- How many engineers do you need to maintain multiple EdTech platforms?
- For 3–4 concurrent live systems: 2 dedicated engineers minimum, one reactive, one proactive. For complex stacks or tight SLAs, add a dedicated QA.
- What’s the difference between EdTech platform maintenance and standard IT support?
- IT support responds to tickets. Maintenance is engineering-level work: fixing bugs, managing deployment risk, and preventing failures before they happen — not after a classroom is already disrupted.
- How do you handle system failures outside business hours?
- P1 failures trigger immediate response regardless of time. P2/P3 are queued for the next business day unless the client requests otherwise.
- Can you maintain systems built by another vendor?
- Yes — that’s the most common scenario. We spend 2–4 weeks on structured onboarding first: mapping architecture, identifying undocumented behavior, and building a knowledge base before touching anything in production.
- What does EdTech platform maintenance typically cost?
- It varies by number of systems, stack complexity, and SLA requirements. The more useful question is what poor maintenance costs — in this engagement, deferred fixes were already affecting school operations before we stepped in. Happy to do a scoping call for your specific situation.
Author

Lucie Tran
Head of Growth of Kaopiz Global
Table of Contents
Don’t miss what’s next!
Thank you! Your form has been submitted successfully.


