


NEWS


2025.02.10

2026.04.14
DeepSeek R1とは?次世代AIモデルのメリット・デメリットと革新技術を解説
AI技術の進化に伴い、さまざまな業界での活用が進んでいます。その中でも、DeepSeek R1は次世代AIモデルとして注目されています。この革新的なAIモデルは、従来の技術と比較して飛躍的に精度や速度が向上しており、企業の業務効率化や意思決定を支援する力を持っています。
本記事では、DeepSeek R1の特徴、メリット、デメリットについて詳しく解説し、どのようにして革新技術を活用できるのかを紹介します。次世代AIを活用したい企業にとって、DeepSeek R1がどのように役立つかを理解するための第一歩となるでしょう。
目次
- DeepSeekとは
- DeepSeek R1とは
- DeepSeek R1の主なメリット
- DeepSeek R1の革新的技術
- DeepSeek R1のデメリットと注意点
- DeepSeek R1がもたらす未来
- カオピーズと一緒にAIの旅を始めましょう!
- FAQ(よくある質問)
DeepSeek R1:次世代AI技術の革新
DeepSeekは、中国のAI企業で、OpenAI、Google Deep Mind、Metaに匹敵するAIモデルの開発を行っています。
DeepSeek社は、ヘッジファンドのマネージャーであるLiang Wenfengによって2023年末に設立されました。同社は人工知能(AI)の研究開発に特化した企業であり、特に大規模言語モデル(LLM – Large Language Models)や先進的なAIアプリケーションに焦点を当てています。
設立からまだ1年ほどしか経ちませんが、同社は「DeepSeek」の名を冠した多くの先進的なAIモデルをこれまでに複数発表しており、その中でもDeepSeek R1とDeepSeek R1 Zeroが最も注目されています。

DeepSeek R1とは
DeepSeek R1は、次世代のAIモデルとして注目されており、その高度な技術は多くの業界で革新をもたらす可能性を秘めています。従来のAIモデルと比較して、DeepSeek R1はより効率的で、精度の高いデータ解析を実現しています。その革新性と導入可能な分野について、以下で詳しく解説します。
DeepSeek R1は、DeepSeekプラットフォームの最初のAIモデルです。DeepSeek R1の特徴は、OpenAIのGPT-4やGoogleのGeminiなどのトップモデルと競合できる能力を持っていることです。先進的な訓練技術とアーキテクチャを採用することで、DeepSeek R1は数学やプログラミングといった複雑な問題を高い精度で解決することができます。
DeepSeek R1の主なメリット
- 低コスト
DeepSeek R1は、従来のAIモデルに比べて少ない計算リソースで高い精度を達成するよう最適化されており、コストを節約し、使用効率を向上させます。DeepSeek V3(DeepSeek R1のベースとなるモデル)の訓練コストは558万ドルで、OpenAIのo1モデルを作成するためのコストの約3~5%に相当します。 - 高性能
テストを通じて、DeepSeek R1は数学タスクやプログラミングタスクにおいてOpenAIのo1モデルと同等の能力を示し、GPT-4oモデルや、強化学習技術で大規模に訓練されていないDeepSeek V3ベースモデルと比較しても、はるかに高い結果を出しています。国際数学試験のテストでは、GPT-4oが13%しか解けなかったのに対し、OpenAI o1は83%を解くことができました。DeepSeek R1は、OpenAIのGPT-4やGoogleのGeminiといった大規模AIモデルと競合できる能力を持っており、訓練技術とアーキテクチャの進歩によりこのような性能を実現しています。
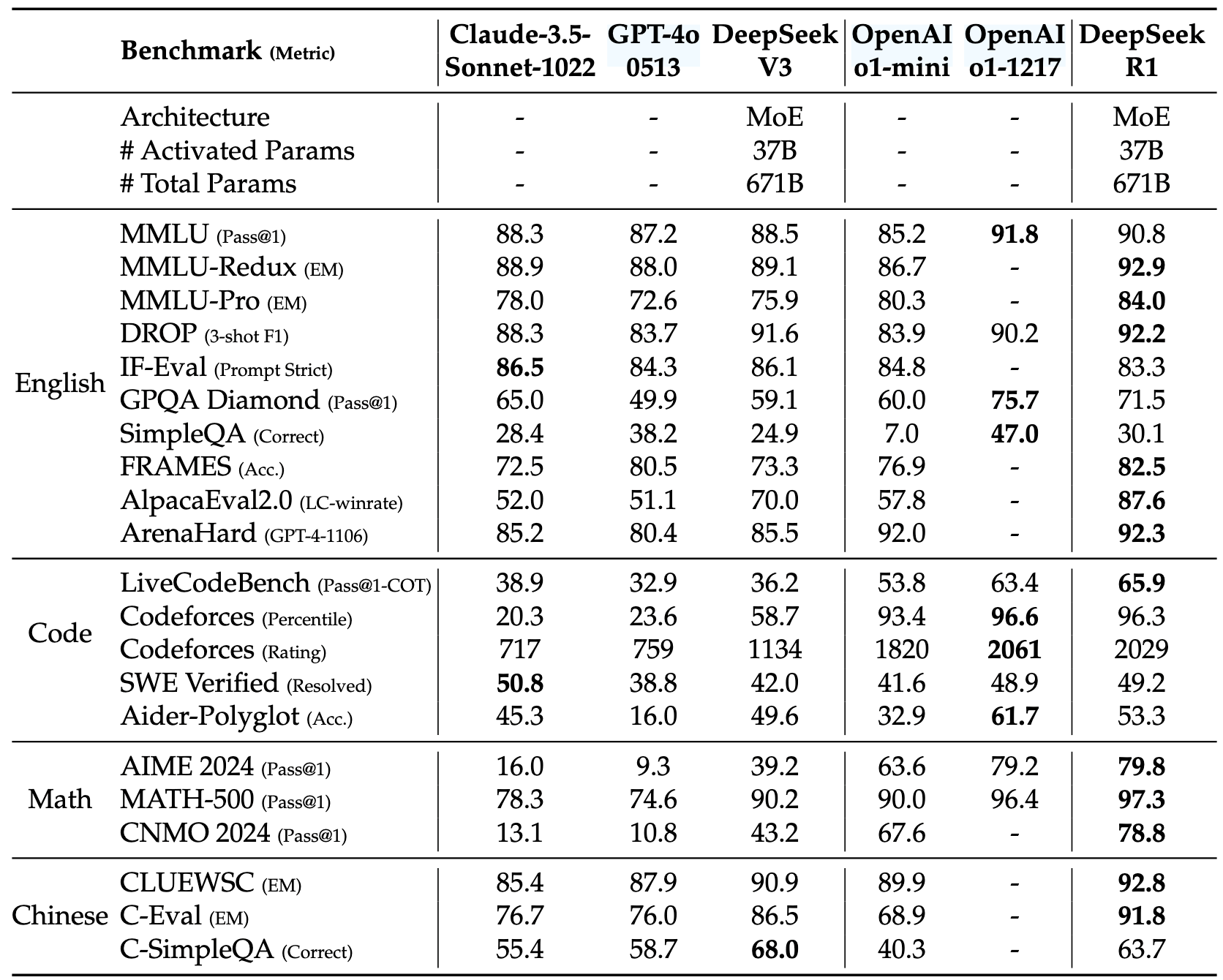
- 簡単にアクセス&使用可能
DeepSeekは、DeepSeek V3およびDeepSeek R1モデルをMITライセンスで公開しており、ユーザーはこれらを無料でダウンロードして利用でき、
商業目的でも使用が許可されています。また、十分な計算インフラがない場合でも、DeepSeekのチャットインターフェースを無料で利用でき、
Deepseekからアクセスできます。
さらに、APIを使用することで、OpenAIのAPIと比較してはるかに安価で利用でき(入力の100万トークンあたり0.14ドル、出力の100万トークンあたり0.28ドル)、GPT-4oに相当するモデルは、入力の100万トークンあたり2.50ドル、出力の100万トークンあたり10ドルのコストがかかります。
DeepSeek R1の革新的技術
DeepSeek R1は、モデルアーキテクチャの設計とトレーニング方法における革新、特に強化学習アルゴリズムの適用により成功を収めました。
DeepSeek R1モデルアーキテクチャ
DeepSeek R1は、基盤となるDeepSeek V3モデルをベースに構築されています。そのため、DeepSeek R1のアーキテクチャはV3と似ています。しかし、DeepSeekの開発チームは、トレーニングとモデルの展開プロセスを最適化するために多くの改良を行いました。注目すべき改良点は以下の通りです:
- 混合専門家モデル(MoE: Mixture of Experts)アーキテクチャ:DeepSeek R1は、タスクごとの最適な「専門家(experts)」を選んで計算を行うことで、計算効率を向上させています。この技術により、モデルは高精度を保ちながらも、計算リソースを節約することができます。
- マルチヘッド潜在アテンション(MLA):自己注意機構を効率化するために、DeepSeek R1では計算負荷を軽減し、メモリの使用を最適化しています。この技術により、処理速度が向上し、より多くの情報を迅速に処理できるようになります。
- 複数トークン予測(MTP):DeepSeek R1は、一度に複数のトークンを生成することで、処理速度を大幅に向上させ、応答時間を短縮しています。これにより、大量のデータを効率よく処理することができます。
- FP8量子化:従来のFP32に比べて最大75%のメモリを節約できるこの技術を用いれば、リソース使用を最適化し、より効率的なAIモデルの運用を実現可能にします。
DeepSeek R1モデルのトレーニング方法
DeepSeek R1のトレーニング方法は、強化学習を通してDeepSeek V3モデルに推論能力を与えることに重点を置いています。
- DeepSeek R1 Zeroの出力は、特に中国語が混在することがありました。
- 推論内容は、時折読みにくく理解しにくいことがありました。
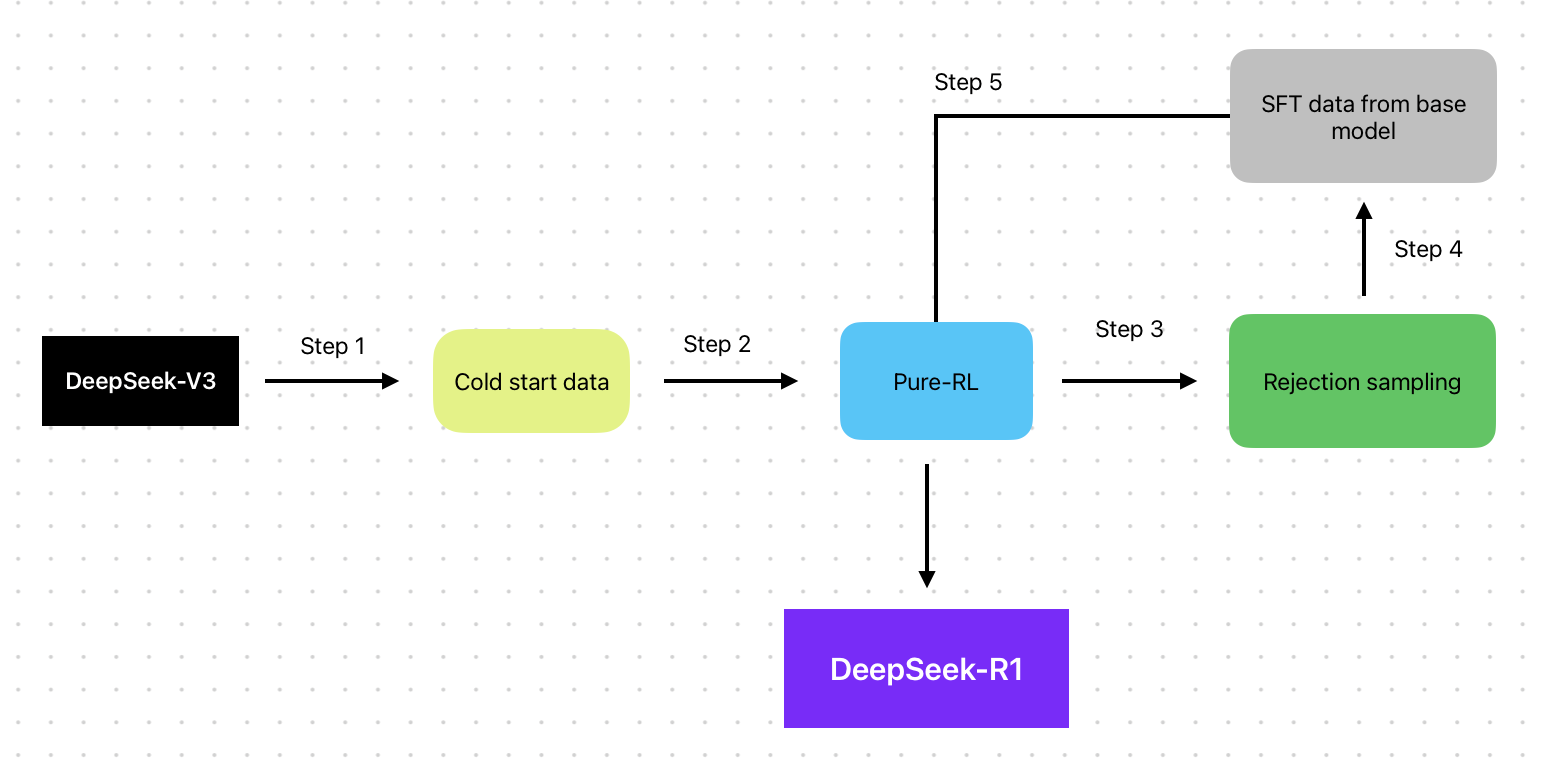
ステップ1:基盤を構築
最初に、数千のコールドスタートデータを使用して、ベースモデル(DeepSeek-V3-Base)をファインチューニングしました。この段階では、データ量は非常に少ないですが、通常の教師あり学習に必要な何百万、場合によっては何十億のラベル付きデータに比べ、ほんの一部です。これにより、モデルの基盤が確立されました。ステップ2:推論能力の向上
次に、強化学習(RL)を用いて、モデルの推論能力を強化しました。この段階は、DeepSeek-R1-Zeroに似た方法を用いて、モデルがさらに優れた推論能力を持つようにしました。
ステップ3:合成データ生成
強化学習が収束に近づくと、拒否サンプリングを使用しました。これにより、モデルが過去の強化学習実行から最適な例を選び、自ら合成データ(ラベル付きデータ)を生成しました。この方法は、OpenAIが小型モデルを使用してO1モデル用に合成データを生成する手法に似ています。
ステップ4:合成データと教師ありデータの統合
新しく生成された合成データは、DeepSeek-V3-Baseの教師ありデータと統合されました。これにより、ライティング、事実確認QA、自己認識といった分野での知識が追加され、モデルは高品質な出力と幅広いドメイン特化型知識を学ぶことができました。
ステップ5:最終調整
最後に、合成データを使用してファインチューニングされたモデルは、さまざまなプロンプトやシナリオに基づいて最終的な強化学習プロセスを実行しました。
DeepSeek R1のデメリットと注意点
DeepSeek R1モデルにはいくつかの制限も存在します。
言語に関する制限
DeepSeek R1は主に英語と中国語のデータで訓練されているため、質問が他の言語で行われた場合でも、時々英語や中国語で回答することがあります。
敏感なテーマに対する回答の回避
DeepSeek R1は、特に中国に関連する政治的・社会的な敏感な問題について、回答を避けたり拒否したりする傾向があります。しかし、Ciscoの研究チームによる実験では、HarmBenchデータセットからランダムに50件の有害なプロンプトを取り出した際、DeepSeek R1は有害なプロンプトを成功裏にブロックすることができませんでした。
計算インフラの要求
DeepSeek R1はモデルのサイズが大きいため、ローカル環境でモデルを実行するためには強力な計算インフラが必要です(DeepSeek R1 671Bを実行するには約6 x H100 80GBが必要です)。DeepSeek R1から精選されたモデルは低性能のハードウェアでも使用可能ですが、これらのモデルは元のDeepSeek R1と同等の能力を持っていません。
DeepSeek R1がもたらす未来
DeepSeekは、AIの進化において大きな突破口を開きました。強化学習を活用することで、大規模言語モデルの推論能力を飛躍的に向上させたのです。特に、DeepSeek R1のようにファインチューニングと強化学習を組み合わせたアプローチは、従来の方法では乗り越えられなかった限界を突破しました。
カオピーズと一緒にAIの旅を始めましょう!
こちらの記事をご覧になられた方々で、強力で効果的、かつコスト効率の良いAIソリューションを探していらっしゃるようでしたら、カオピーズのサービス利用をご検討ください。
カオピーズは、AIとDX分野の先駆者であり、企業の運営効率を向上させる賢く創造的なソリューションを提供することを約束します。
経験豊富で専門性の高いチームを擁し、カオピーズは革新的なAIアプリケーションの開発に注力し、ビジネスプロセスの最適化、コスト削減、競争力の向上を支援しています。AIが次世代ビジネスにおいて多大な影響力を有しているを弊社は理解しておりますので、AIを最も効果的に活用できるようサポートいたします。
今すぐカオピーズにご連絡いただき、AIソリューションを導入し、ビジネスの成長を加速しましょう!お見積もり・ご相談はこちら
FAQ(よくある質問)
- Q1. DeepSeek R1はどのような業界で活用されていますか?
- DeepSeek R1は、金融、製造業、医療、物流など、多岐にわたる業界で活用されています。特に、ビッグデータ解析が求められる業界での利用が進んでいます。
カオピーズでは、AIソリューションを提供し、業界ごとのニーズに応じたカスタマイズを行っています。 - Q2. DeepSeek R1を導入する際の最大の課題は何ですか?
- 最大の課題は、高額な初期投資と専門知識を持つ技術者の確保です。また、AIモデルの運用にはデータの整備も重要な要素となります。
カオピーズでは、導入支援や技術者のトレーニングサービスを提供し、スムーズな導入をサポートしています。 - Q3. DeepSeek R1は今後どのように進化していくと予想されますか?
- 今後、DeepSeek R1はさらに高度なアルゴリズムを取り入れ、より多くの業界に対応した多機能型AIモデルへと進化すると考えられます。また、データ解析の精度や速度も改善され、さらに効率的なシステムが期待されます。
カオピーズは、常に最先端のAI技術を取り入れ、企業の成長を支援しています。

よく読まれている記事

ブログ
26.04.14
オフショア開発とは?意味やメリット、失敗しない進め方を紹介
オフショア開発とは何か?定義・メリット・デメリットから、契約形態5種、ベトナム等の委託先国比較、費用相場、導入6ステップまでCTO・IT責任者向けに徹底解説。失敗しない選び方と2026年最新トレンドも紹介。

ブログ
26.03.30
24/365とは?システム安定稼働に必要な運用体制・コストを解説
24/365とは「24時間365日」を意味する言葉で、システム運用の現場でよく使われます。本記事では基本定義から具体的な業務、自社運用と外注のコスト比較、AI活用の最新監視サービスまでを解説します。
掲載.jpg)
【お知らせ】
26.03.27
『経済界』2026年5月号(3月23日発売)掲載:ベトナムオフショアでレガシー刷新を推進するカオピーズ代表取締役チン・コン・フアンの挑戦
ベトナムオフショア開発でレガシー刷新とDX推進を支援するカオピーズ。『経済界』掲載インタビューで成長戦略と強みを紹介。
お問い合わせ
