


NEWS



近年、生成AIやChatGPTなどの技術革新により、企業におけるRAG(Retrieval-Augmented Generation)の導入が大きな注目を集めています。
しかし、「自社でRAGを導入するにはどのような技術スタックが必要か」「システム構築やデータ統合をどう進めればよいのか」と悩むエンジニアやプロジェクトマネージャーも少なくありません。
本記事では、RAGの導入を検討している方のために、全体像の理解から必要となる技術スタックの選定、システム構築の流れ、具体的な開発ステップ、さらにはデータ統合のポイントまで、実践的な導入方法について徹底解説します。
RAG導入のステップや手順、システム構築における注意点についてもわかりやすく解説しているため、自社の業務や要件に合ったRAGソリューションをスムーズに実装したい方は、ぜひ本記事を参考にしてください。
目次
RAGとは何か
近年、大規模言語モデル(LLM)の進化により、企業は新たな形の検索・質問応答システムの導入を検討するようになっています。その中でも「RAG(Retrieval-Augmented Generation)」は、外部データベースから関連情報を検索し、その情報をもとに回答を生成する仕組みとして注目を集めています。特に、自社データや独自ナレッジをダイナミックに活用したい企業にとって、RAGの導入は競争力強化の有力な武器となり得ます。
RAGは一般的なチャットAIやFAQシステムとは異なり、事前学習済みのLLMに加え、ドキュメントや社内データなどをリアルタイムで検索し参照できることで、最新情報やナレッジの反映が可能です。これにより、情報鮮度・正確性の向上、業務効率化など多くのメリットがあります。

RAG導入のメリット
ここでは、企業がRAGを導入することで得られるメリットを具体的に解説します。単なる情報生成AIやFAQシステムを超えた、企業独自の強みを引き出す点がRAGの最大の魅力です。
まず、RAG最大のメリットは「最新かつ正確な回答生成」です。従来のFAQやAIチャットボットは、学習時点のデータしか参照できず、情報の陳腐化や限定的な回答につながる課題がありました。一方、RAGは外部リポジトリや社内ドキュメントを検索するため、規程や製品マニュアルの更新、法令改正など、刻一刻と変わるナレッジの反映が自動的に可能です。
次に、「業務効率の劇的な向上」も挙げられます。問い合わせ対応やマニュアル検索などの場面で、膨大なドキュメントを都度確認する人的コストが削減され、業務工数が大幅に圧縮されます。さらに、意思決定の精度向上やナレッジ活用効果も見込めます。
情報漏洩防止やアクセス制御などの「セキュリティ要件対応」もRAGの強みです。企業内のデータを厳密に管理しつつ検索応答できる仕組みを構築でき、クラウドやオンプレミスのセキュリティポリシーに柔軟に対応します。カオピーズでは、各企業の情報管理ポリシーやITインフラに合わせた最適なRAG導入を支援しています。
これらのメリットを最大限に引き出すためには、導入目的と要件を明確にし、自社に最適なRAG構成を設計することが重要です。

RAG導入に必要な技術スタック
RAGシステムを成功裏に導入するためには、複数の技術要素がシームレスに連携する堅牢な「技術スタック」の構築が求められます。ここでは主要コンポーネントを順に解説します。
まず、中心となるのが「大規模言語モデル(LLM)」です。OpenAIのGPT-3/GPT-4やGoogle Geminiなど高性能なプロバイダーの選定とAPI利用が一般的です。業務データが外部に渡るリスクへの配慮や、オンプレミス運用(Llama 2等のオープンソース利用)の実績も増えており、カオピーズでは各種業態に応じた提案・構築が可能です。
次に肝となるのが「ベクトルデータベース(Vector DB)」です。ドキュメントやFAQデータは埋め込みモデル(embedding model)を通じてベクトル化し、Pinecone、Weaviate、FAISS、Elasticsearch等で効率的な類似検索が行えます。カオピーズのRAG導入支援では、データ規模や検索負荷、コスト観点から最適なベクトルDBを構成します。
第三に、「検索エンジン・情報検索API」の設計が不可欠です。ベクトルDBへのクエリ生成・検索条件の設計、結果のサンプリング、精度向上のための再ランキング等がここで行われます。検索性能・レーテンシを担保することで、ユーザー体験の質が決まります。
さらに「データ前処理・ETL」も要となります。ドキュメントPDFや業務DB等、異なるフォーマットの情報を正規化し、AI学習・検索に適した形に変換します。カオピーズでは既存の基幹システムとの連携や、セマンティックサーチ向けメタデータ自動抽出にも対応しています。
最後に、「ユーザーインターフェース(UI)とAPI」設計です。RAG検索・応答体験を業務現場のワークフローやSaaS(例:Notion・Slack連携等)とスムーズに統合するためのアプリやAPIゲートウェイもカオピーズの実績領域です。
このように、RAGの技術スタックは多層にわたるため、現場の運用要件や拡張性を踏まえた設計が成功の鍵を握ります。
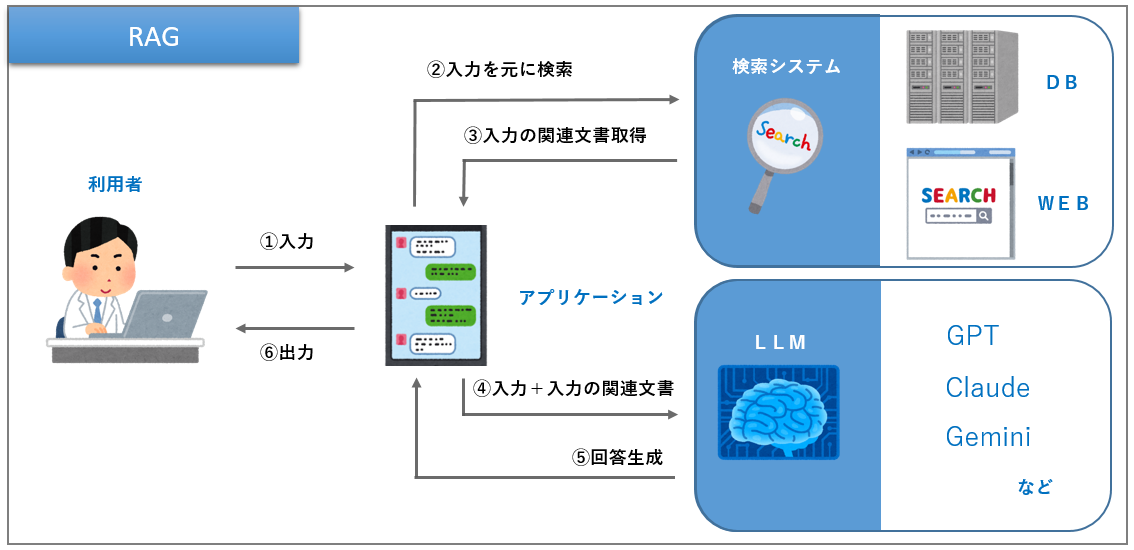
RAGシステムの構築手順
RAG導入における開発・構築手順(開発フロー)は、プロジェクト管理やエンジニア視点で理解しておくべき重要事項です。以下では、全体の開発ステップを系統的に示します。
【1. 課題・要件定義】 まず、自社でRAGを導入する明確な目的と、解決したい業務課題(例:ナレッジ活用、問い合わせ迅速化等)を洗い出します。対象データの種類・量、必要な検索精度、可用性、セキュリティ条件など、多角的に要件を整理します。
【2. データ準備・前処理】 マニュアルやドキュメント、FAQ等を一元管理し、PDF・Word・HTMLなど異なる形式をテキストデータとして抽出・正規化します。ノイズ除去やデータクレンジング、粒度調整もこの段階で行います。
【3. ベクトル化・DB登録】 前処理したテキストデータを埋め込みモデル(BERT、sentence-transformers、OpenAI Embeddingなど)でベクトル化し、選定したベクトルデータベース(例:Pinecone、Weaviate、Elasticsearch+ANN plugin)へインデックス登録します。
【4. 検索アルゴリズム設計】 LLMによる検索クエリ生成、類似度のしきい値・ランキング最適化等を実装。検索制度を高めるため、ハイブリッド検索(キーワード+ベクトル)や再ランキングアルゴリズムの適用も検討します。
【5. LLM統合・応答生成】 検索APIから取得した最関連ドキュメントをLLMのプロンプトに埋め込み、ユーザーの質問に応じた自然でコンテキスト豊かな回答を生成します。この際、不適切応答のフィルタや検閲機構も実装可能です。
【6. UI/API組み込み・現場統合】 既存業務ツールとの連携や独自チャットUI(Webアプリ/Slack bot等)へRAG機能を統合します。APIドキュメントの整備や認証ルール実装も含め、安全な顧客体験を担保します。
【7. 品質評価・デプロイメント】 PoC(概念実証)段階でテストデータによる精度評価・A/Bテストを実施し、本番リリース前にログ取得や改善ポイントを抽出します。運用後も継続的な再学習やメンテナンス体制の設計が重要です。
カオピーズでは、上記の各ステップにおいてカスタム開発や既存基盤とのアジャイルな連携構築、将来の拡張性を見越した設計を行っています。
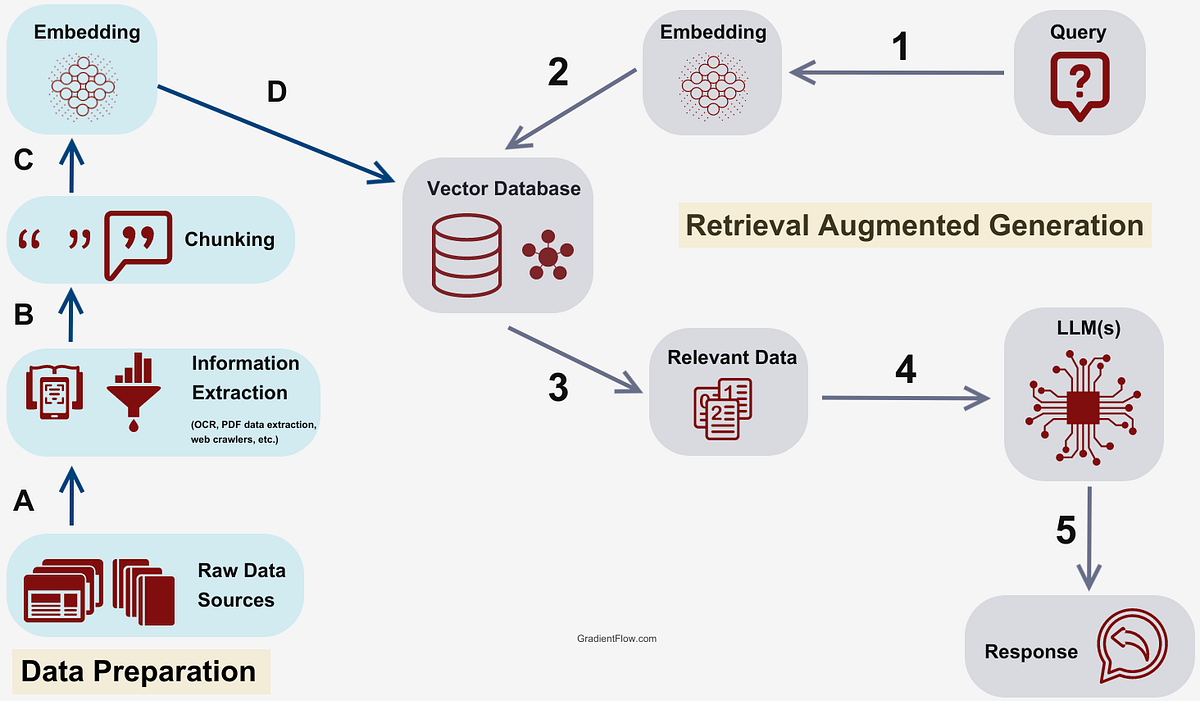
RAG導入時の注意点と課題
RAG導入は多くのメリットがある一方で、十分な計画とリスクマネジメントが不可欠です。ここでは、トラブルを未然に防ぎ、最大の成果を上げるための主要な注意点・課題を整理します。
最大のリスクは「データ品質・管理の難しさ」です。不適切なデータ前処理や古い情報・重複データ混入は、検索精度・回答品質を著しく損ないます。現場運用に合わせて粒度を調整し、継続的なメンテナンス体制を整備する必要があります。
「個人情報や機密情報」の扱いにも注意が必要です。特に法規制や情報統制が求められる業種では、アクセス権限・マスキング・暗号化などをシステムレベルで担保しなければなりません。カオピーズでは、ISMS等の情報セキュリティ基準に準拠した設計を推進しています。
「埋め込みモデルの選定・微調整」も高精度な検索の鍵です。自社特有の業界用語や専門語彙を学習したカスタムembeddingモデルによる最適化は、RAG導入の成否を分けます。同時に、LLMの応答メカニズムやプロンプト設計ノウハウも欠かせません(詳細解説:Forbes Japan)。
検索速度(レーテンシ)の最適化も重要です。データ規模やアクセス頻度に応じたベクトルDBスケーリングや、APIキャッシュ戦略、バックエンドの最適チューニングも視野に入れるべきです。
導入ROIを最大化するには、精度評価基準と改善ループ設計が必要です。PoC段階での評価と運用後の改善をカオピーズはDevOpsの観点で支援します。

RAG導入成功事例
実際にRAGを導入し、大きな成果を上げている企業の事例を紹介します。導入の現場イメージを掴み、実践的なヒントを得たいエンジニア・PMの参考になります。
製造業A社では、膨大な製品マニュアル・技術文書が数十万ページに及び、現場スタッフの問い合わせ対応負荷が慢性化していました。カオピーズが提案・構築したRAGシステムでは、既存のSharePoint・社内DBから情報を自動抽出・ベクトル変換し、安全なクローズド環境での検索・AI応答を実現。現場スタッフの自己解決率が向上しただけでなく、対応コストを年間2,000時間削減できました。
ITサービス企業B社では、APIドキュメント等の頻繁な改訂に伴うFAQ更新作業の手間が課題でした。カオピーズは独自のETLパイプライン・自動データ統合機構を構築し、RAGとSaaS(Confluence連携)をシームレスに統合。わずか3カ月でPoCから本番運用に移行し、ナレッジ共有と内部QAが一体化。問い合わせリードタイムが50%短縮しました。
これらの事例に共通する成功要因は、「適切な技術スタック選定・工数最適化・現場定着のためのカスタマイズ力」です。カオピーズのRAG導入は要件定義、システム構築、運用定着まで一気通貫の支援で評価されています。
まとめ
本記事では、RAG(Retrieval-Augmented Generation)の仕組みと、その導入によるメリット、必要な技術スタック、実践的な開発ステップ、注意点までを体系的に解説しました。
RAGは大規模言語モデルと社内データの連携により、最新かつ正確な情報の検索・応答が可能となり、業務効率化やセキュリティ要件の両立にも大きく寄与します。
成功にはデータ管理・ベクトルDB・LLM・UI統合など各要素の技術的適合と、継続的な運用改善が不可欠です。
事例に見るように、現場の業務負荷軽減やナレッジ共有といった即効性ある成果が見込まれる一方、事前の要件定義やPoC評価が導入成功の鍵を握ります。
RAG導入方法の全体像とポイントを押さえ、貴社DX推進にぜひお役立てください。
自社データ活用や業務自動化を本格的に進めたい企業様は、RAG導入の専門知見を持つカオピーズまでお気軽にご相談ください。
最適な技術スタックのご提案からPoC、導入・運用までワンストップでご支援します。
導入事例や開発ノウハウをわかりやすくご説明する無料相談も実施中です。
まずはお問い合わせフォームよりご連絡ください。
よくある質問(FAQ)
- RAGを導入するために必要な主な技術スタックは何ですか?
- RAG(Retrieval-Augmented Generation)の導入には、自然言語処理(NLP)フレームワーク、検索エンジン(ElasticsearchやFAISSなど)、API連携ツール、クラウドサービス、データベース管理システムなどの技術スタックが必要です。
- RAG導入の一般的な開発手順はどのようになりますか?
- RAGの開発手順は、まず要件定義とデータ収集を行い、データ整備と前処理、検索システム構築、生成モデル統合、API開発、テスト・検証、運用環境へのデプロイというステップで進めます。
- RAG導入時のシステム構築で注意すべきポイントは何ですか?
- データの品質管理やセキュリティ、検索エンジンと生成モデル間の連携方法、スケーラビリティの確保、運用保守のしやすさなど、安定稼働と今後の拡張を見据えた設計が重要です。
- RAGを導入する際のデータ統合のコツはありますか?
- データ統合では、異なるソースからの情報を正規化し、統一フォーマットで管理することがポイントです。また、データのメンテナンス性を高めるため、定期的な更新やクレンジングも重要です。
- RAGの導入支援やシステム構築を依頼したい場合はどうしたらよいですか?
- RAG導入やシステム構築、技術スタックの選定、開発手順の策定までを専門チームが支援しています。カオピーズでは企業ごとのニーズに合わせたRAG導入支援サービスをご提供していますので、ぜひご相談ください。

よく読まれている記事

ブログ
26.03.30
24/365とは?最も効率的なシステム運用を実現する完全ガイド
24/365とは?基本からリスクや具体的な運用内容をわかりやすく解説。自社運用と外注でコストを比較し、最適な選択ができるようになります。
掲載.jpg)
【お知らせ】
26.03.27
『経済界』2026年5月号(3月23日発売)掲載:ベトナムオフショアでレガシー刷新を推進するカオピーズ代表取締役チン・コン・フアンの挑戦
ベトナムオフショア開発でレガシー刷新とDX推進を支援するカオピーズ。『経済界』掲載インタビューで成長戦略と強みを紹介。

ブログ
26.03.17
オフショア開発とは?メリット・失敗しない進め方・ベンダー選定のコツを徹底解説
オフショア開発の概要からメリット・デメリット、成功の進め方、主要な委託先国までを徹底解説。失敗を避けるポイントも紹介します。
お問い合わせ